

티스토리 뷰
데이터합치기
기존의 데이터
데이터 프레임 3개를 만든다.
df1=pd.DataFrame([['a',1],['b',2]],columns=['letter','number'])
df2=pd.DataFrame([['c',3],['d',4]],columns=['letter','number'])
df3=pd.DataFrame([['e',5,'!'],['f',6,'@']],columns=['letter','number','etc'])


데이터 프레임 합치기
pd.concat()을 사용하면 데이터프레임을 합칠 수 있다. default값은 열을 기준으로 뭉친다.

inner 키워드를 쓰면 중복을 없앤다.

Nan이 사라진 것을 볼 수 있다.

그러나 중복 인덱스가 존재하기에 인덱스로 값을 추출하기가 어렵기에 인덱스를 재설정한다.
#인덱스 재지정
df_rowconcat=pd.concat([df1,df2,df3],join='inner',ignore_index=True)
df_rowconcatignore_index=True
하면 인덱스를 재설정한다.

행을 기준으로 합치기
#열로 연결하기
df4=pd.DataFrame({'age':[20,21,22]},index=['amy','james','david'])
df5=pd.DataFrame({'phone':['010-111-1111','010-222-2222','010-333-3333']},index=['amy','james','david'])
df6=pd.DataFrame({'job':['student','programmer','ceo','designer']},index=['amy','james','david','J'])



axis=1을 설정하면 행기준으로 합칠 수 있다.

inner조인을 하면 같은 갯수만 합친다.
#공통된 열 기준으로 연결하기
#pd.merge(left,right,on=기준칼럼,how=연결방법)
#2개의 데이터 프레임을 연결한다.
df=pd.read_csv('scores.csv')
df7=df.loc[[1,2,3]][['name','eng']]
df8=df.loc[[1,2,4]][['name','math']]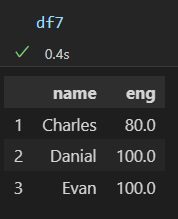

merge를 통해 공통된 열을 기준으로 합칠 수 있다.

레프트 조인
왼쪽(df7)에 charles, danial, evan을 기준으로
라이트 조인
오른쪽(df8)에 charles, danial, henry을 기준으로
조인한다.


열을 행으로 돌리기
melt 키워드를 쓴다.

name을 고정하려면 id_vars를 입력한다. 맨 위를 보면 name이 있다.


#컬럼명 변경
#var_name=컬럼명
df.melt(id_vars='name',value_vars=['kor','eng'],var_name='subject',value_name='score')
행을 열로 돌리기(pivot)
df=pd.read_csv('scores.csv')
df=df.head(2)
df=df.melt(id_vars='name',var_name='subject',value_name='score')
def get_grade(x):
if x>=90:
grade='A'
elif x>=80:
grade='B'
elif x>=70:
grade='C'
elif x>=60:
grade='D'
else:
grade='F'
return grade
df['grade']=df['score'].apply(get_grade)
df=df.sort_values('name')
df



transpose 행을 전치시킨다.

피벗테이블 활용하기
현재 데이터
import pandas as pd
df=pd.DataFrame({'item':['shirts','shirts','shirts','shirts','shirts','pants','pants','pants','pants'],
'color':['white','white','white','black','black','white','white','black','black'],
'size':['small','large','large','small','small','large','small','small','large'],
'sale':[1,2,2,3,3,4,5,6,7],
'inventory':[2,4,5,5,6,6,8,9,9]})
df


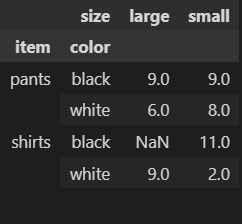
df.pivot_table(index=['item','color'],columns='size',values='inventory',aggfunc=sum)피벗테이블로 인덱스(왼쪽)은 아이템과 색상, 컬럼(맨위)는 사이즈를 하고 각각의 재고를 조회할 수 있다.
CSV파일을 받아서 분석해보기
df=pd.read_csv('titanic.csv')
df_titanic=df[['Survived','Pclass','Sex','Age','Embarked']]
df_titanic=df_titanic.dropna()
df_titanic.head()
원래 데이터

생존자별 클래스로 조회하기

객실 등급별 생존율
#성별 객실등급별 생존율
df_titanic.pivot_table(index='Sex',columns='Pclass',values='Survived',margins=True)
Group by 사용하기
데이터준비
df=pd.read_csv('titanic.csv')
df_titanic=df[['Survived','Pclass','Sex','Age','Embarked']]
df_titanic=df_titanic.dropna()
df_titanic.head()
칼럼명.groupby(그룹기준칼럼).통계적용칼럼.통계함수
#df.groupby(그룹기준칼럼).통계적용칼럼.통계함수
#객실등급(pclass)별 승선자 수를 구한 결과
df1=df.groupby('Pclass').Survived.count().to_frame()
df1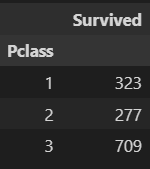
#객실등급별 생존자 수를 구한결과
df2=df.groupby('Pclass').Survived.sum().to_frame()
df2#객실등급별 생존율 구한 결과
df3=df.groupby('Pclass').Survived.mean().to_frame()
df3
여러 칼럼을 동시에 추출하기
#객실등급별 탑승자수, 생존자수, 생존율 구하기
df4=pd.concat([df1,df2,df3],axis=1)
df4.columns=['승선자수','생선자수','생존율']
df4
columns로 인덱스를 설정한다.
df5=df.groupby('Sex').Survived.count().to_frame()
df5df6=df.groupby('Sex').Survived.sum().to_frame()
df6df7=df.groupby('Sex').Survived.mean().to_frame()
df7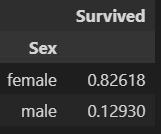
사용자 정의 함수를 적용하기
#그룹에 사용자 정의 함수 정의하기
#df.groupby(그룹기준칼럼).통계적용컬럼.agg(사용자정의함수,매개변수)
def my_mean(values):
return sum(values)/len(values)
df.groupby(['Sex','Pclass']).Survived.agg(my_mean)
맨 뒤에 agg(함수, 매개변수)를 입력하면 된다.
그룹오브젝트 출력하기
#그룹 오브젝트 출력하기
df20=df[:20]
df20.head()

#그룹별 출력(1등석)
df20.groupby('Pclass').get_group(1)
get_group()을 사용하면 값을 출력한다. 1은 1등석을 의미한다.
- Total
- Today
- Yesterday
- Python
- 오블완
- 사회심리학
- c++
- 파이썬
- 데이터분석
- 여인권
- 백준
- K-MOOC
- 일본어
- 코딩테스트
- 일문따
- 강화학습
- 보세사
- 회계
- C
- jlpt
- C/C++
- 통계학
- 인지부조화
- 류근관
- 인프런
- 윤성우
- 일본어문법무작정따라하기
- 티스토리챌린지
- 정보처리기사
- stl
- 뇌와행동의기초
- 열혈프로그래밍
- 심리학
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |