

티스토리 뷰
1장 들어가기
1.1 데이터 시대의 도래
데이터는 어디서나 쓰인다
스마트홈, 스마트 카 등 뿐 아니라 어디에나 있다. 그러니 중요하다
1.2 데이터 과학이란?
데이터과학자
:지저분한 데이터에서 통찰(Insight), 즉 유용한 규칙을 발견하려고 하는 사람이다.
데이터마이닝을 통해 투표, 상품판매, 이주패턴 찾기 등 여러가지에 응용이 가능하다
1.3 동기부여를 위한 상상:데이텀 주식회사
데이터 과학자들을 위한 소셜네트워크 회사에서 일한다고 가정해보자. 하지만 이 회사는 데이터 과학을 써보지 않았다. 우리가 몇 가지를 처음부터 구현한다 생각해보고 실습해보자.
1.3.1 핵심인물 찾기
데이터 과학자 중의 핵심인물은 누구일까? 사용자 중에 친구가 많은 사람은 누구일까? 이를 한 번 구현해보자.
users=[
{"id":0,"name":"Hero"},
{"id":1,"name":"Dunn"},
{"id":2,"name":"Sue"},
{"id":3,"name":"Chi"},
{"id":4,"name":"Thor"},
{"id":5,"name":"Clive"},
{"id":6,"name":"Hicks"},
{"id":7,"name":"Devin"},
{"id":8,"name":"Kate"},
{"id":9,"name":"Klein"}
]
우리의 소설 네트워크를 사용하는 유저의 명단이 있다. 10명의 일련번호와 이름이 적혀있다.
이들 중 누구와 누구가 친구관계가 있는지도 리스트가 있다.
friendship_pairs=[(0,1),(0,2),(1,2),(1,3),(2,3),(3,4),
(4,5),(5,6),(5,7),(6,8),(7,8),(8,9)]
위를 해석하면
0번(Hero)와 1번(Dunn)은 친구다. 이는 (0,1)로 나타낸다.
마찬가지로 (0,2) Hero와 Sue도 친구다.

이를 시각화 하면 위와 같다.
하지만 컴퓨터가 리스트를 처리하기엔 매번 완전탐색을 해야 하기 때문에, 딕셔너리(해시테이블)로 만들면 이를 탐색하기가 더 쉬워진다.
딕셔너리 만들기
friendship={user["id"]:[] for user in users}
friendship
위의 코드를 돌리면 빈 리스트가 만들어진다.
{0: [], 1: [], 2: [], 3: [], 4: [], 5: [], 6: [], 7: [], 8: [], 9: []}
이제 빈 리스트에 각각의 친구를 삽입해보자
for i,j in friendship_pairs:
friendship[i].append(j)
friendship[j].append(i)
그렇다면 friendship은 다음과 같이 나온다.
{0: [1, 2], 1: [0, 2, 3], 2: [0, 1, 3], 3: [1, 2, 4], 4: [3, 5], 5: [4, 6, 7], 6: [5, 8], 7: [5, 8], 8: [6, 7, 9], 9: [8]}
처음에 (0,1) 있다면, i=0, j=1이 될 것이다.
그렇다면
0:[1] 이런식으로 채워지고 그 아래줄에서
1:[0]으로 채워진다.
이걸 반복문 끝까지 채운다.
위의 결과처럼 0, Hero는 친구가 2명이 있고, 1, Dunn은 친구가 3명이 있는 것이 보인다. 그렇다면 친구가 몇 명있는지도 한 번 리턴해보자.
딕셔너리 안에 있는 리스트의 원소의 갯수를 세어보자.
def number_of_friend(user):
user_id =user["id"]
friend_ids=friendship[user_id]
return len(friend_ids)
total_connections=sum(number_of_friend(user) for user in users)
total_connection은 24가 나온다.
이를 user의 수로 나누면,
num_users=len(users)
avg_connections= total_connections/num_users
avg_connections
2.4
한 명당 친구는 평균적으로 2.4명이다.
위에서 구현한 리스트의 원소의 수를 구하는 함수로 각각의 수도 같이 구해보자
num_friend_by_id = [(user["id"], number_of_friend(user))
for user in users]
num_friend_by_id
[(0, 2), (1, 3), (2, 3), (3, 3), (4, 2), (5, 3), (6, 2), (7, 2), (8, 3), (9, 1)]
각각의 번호와 친구의 수가 리턴이 된다.
이를 내림차순으로 한 번 출력해보자.
num_friend_by_id.sort(
key=lambda id_and_friends:id_and_friends[1],reverse=True
)
num_friend_by_id
[(1, 3), (2, 3), (3, 3), (5, 3), (8, 3), (0, 2), (4, 2), (6, 2), (7, 2), (9, 1)]
여기서 key=lambda 이 부분은 어떤 부분 중심으로 정렬을 할지를 알려준다.
id_and_friends[0]은 ‘일련번호’가 있는 곳으로 0,1,…9 왼쪽을 말한다.
id_and_friends[1]은 ‘빈도수’가 있는 곳으로 오른쪽의 3,3,3,3… 등이 있는 곳이다.
빈도수를 기준으로 정렬해야 하기에 오른쪽을 넣은 것이다.
위의 데이터 출력을 본 결과 1,2,3,5,8 등이 친구가 제일 많다. 이들이 보다 중심위치라 할 수 있다.
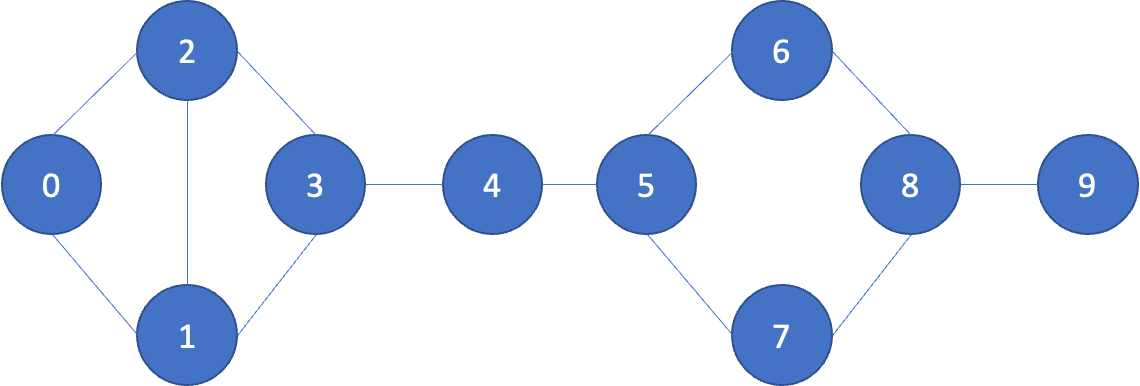
그러나 그림과 같이 4가 중심처럼 보이기도 한다.
이를 나타내는 것도 뒷장에서 배운다고 한다.
1.3.2 데이터 과학자 추천하기
사용자간의 친구가 더 많아졌으면 좋겠다. 그렇다면 서로 추천을 해주는 시스템을 만드려면 어떻게 해야할까?
users=[
{"id":0,"name":"Hero"},
{"id":1,"name":"Dunn"},
{"id":2,"name":"Sue"},
{"id":3,"name":"Chi"},
{"id":4,"name":"Thor"},
{"id":5,"name":"Clive"},
{"id":6,"name":"Hicks"},
{"id":7,"name":"Devin"},
{"id":8,"name":"Kate"},
{"id":9,"name":"Klein"}
]
위에서 사용했던 기존의 유저들의 데이터를 그대로 사용하고, 서로 추천을 해주는 시스템을 만들어보자.
friendship
{0: [1, 2], 1: [0, 2, 3], 2: [0, 1, 3], 3: [1, 2, 4], 4: [3, 5], 5: [4, 6, 7], 6: [5, 8], 7: [5, 8], 8: [6, 7, 9], 9: [8]}
그리고 그 관계를 friendship에 저장하였다.
이를 바탕으로 친구를 추천해주는 코드를 짜보자.
def foat_ids_bad(user):
return [foaf_id for friend_id in friendship[user["id"]]
for foaf_id in friendship[friend_id]]
foat_ids_bad(users[0])
[0, 2, 3, 0, 1, 3]
위의 코드가 리스트컴프리핸션이라 이해하기 어렵다면, 이는 아래와 같은 코드이다
def foat_ids_bad2(user):
a=[]
for friend_id in friendship[user["id"]]:
for foaf_id in friendship[friend_id]:
a.append(foaf_id)
return a
foat_ids_bad2(users[0])
[0, 2, 3, 0, 1, 3]
위의 코드를 해석해보자.
users[0]의 값이 매개변수로 입력되었다.
users[0]
{'id': 0, 'name': 'Hero'}
이 딕셔너리가 전달된다. 여기서 id에 해당하는 값이 첫번째 for문인 friendship[user[id]]에 들어간다.
그럼 friendhship[0]이 전달되고, 이는[1,2]를 의미한다.
그럼 다시 friendship[1] =[0,2,3]이고 friendship[2]=[0,1,3]이니 이 값이 추가 된다.
하지만 위의 출력값은 중복값을 보인다. 0을 2번 3을 2번 출력한다. 중복값을 없애는 코드를 출력해보자.
from collections import Counter
def friends_of_friends(user):
user_id = user["id"]
return Counter(
foaf_id
for friend_id in friendship[user_id]
for foaf_id in friendship[friend_id]
if foaf_id!=user_id
and foaf_id not in friendship[user_id]
)
print(friends_of_friends(users[3]))
위의 코드를 해석해보자.
Counter이란 자료구조는 빈도수를 세어준다고 한다.(잘 몰라서 구글링 해봤다)
for문은 위의 설명과 같다. 매개변수로 users[3]를 넣어보자.
{0: [1, 2], 1: [0, 2, 3], 2: [0, 1, 3], 3: [1, 2, 4], 4: [3, 5], 5: [4, 6, 7], 6: [5, 8], 7: [5, 8], 8: [6, 7, 9], 9: [8]}
users[3]의 id는 3이고, 이에 연결된 id는 [1,2,4]가 있다.
맨 처음에 for friend_id in friendship[user_id]에 3이 전달되고
for flat_id in friendship[friend_id]에 그 안에 있던 1이 전달된다.
1:[0,2,3]이니까 이를 리스트에 추가한다.
그러나 뒤에 if 조건절이 있기에 이를 만족해야 한다.
foaf_id ≠user_id, foat_id는 지금 1이고 user_id는 3이다. 그리고 friendship[user_id]에 있으면 안된다. user_id가 3이었으므로, [1,2,4]는 추가하지 않는다.
그래서 0은 추가하고 2와 3은 추가하지 않는다. 이러한 방식으로 나머지 2와 4에 대해서도 판별을 한다.
Counter({0: 2, 5: 1})
이에 나오는 결과값이다.
그렇다면 관심사별로 서로 연결시켜주는 프로그램도 만들어보자.
interests = [
(0, "Hadoop"), (0, "Big Data"), (0, "HBase"), (0, "Java"),
(0, "Spark"), (0, "Storm"), (0, "Cassandra"),
(1, "NoSQL"), (1, "MongoDB"), (1, "Cassandra"), (1, "HBase"),
(1, "Postgres"), (2, "Python"), (2, "scikit-learn"), (2, "scipy"),
(2, "numpy"), (2, "statsmodels"), (2, "pandas"), (3, "R"), (3, "Python"),
(3, "statistics"), (3, "regression"), (3, "probability"),
(4, "machine learning"), (4, "regression"), (4, "decision trees"),
(4, "libsvm"), (5, "Python"), (5, "R"), (5, "Java"), (5, "C++"),
(5, "Haskell"), (5, "programming languages"), (6, "statistics"),
(6, "probability"), (6, "mathematics"), (6, "theory"),
(7, "machine learning"), (7, "scikit-learn"), (7, "Mahout"),
(7, "neural networks"), (8, "neural networks"), (8, "deep learning"),
(8, "Big Data"), (8, "artificial intelligence"), (9, "Hadoop"),
(9, "Java"), (9, "MapReduce"), (9, "Big Data")
]
각각의 관심사로 사람을 연결해줄 수 있다.
0인 Hero는 Hadoop,Big Data, HBase, Java 등을 좋아한다.
9와 서로 아는 친구는 없지만 Java와 Big Data라는 서로 같은 관심사를 갖고 있다. 이 둘은 서로 친구가 된다면 어떨까?
def data_scientists_who_like(target_interest):
return [user_id
for user_id, user_interest in interests
if user_interest==target_interest]
data_scientists_who_like("Java")
[0, 5, 9]
자바를 좋아하는 사람이 추천이 됐다.
하지만 이는 리스트로 구현됐기에 탐색시간이 길다.
해시테이블로 만들기 위해 딕셔너리를 사용해보자. 그렇다면 탐색시간이 빨라진다.
from collections import defaultdict
user_ids_by_interest = defaultdict(list)
for user_id, interest in interests:
user_ids_by_interest[interest].append(user_id)
user_ids_by_interest
defaultdict(list, {'Hadoop': [0, 9],
'Big Data': [0, 8, 9],
'HBase': [0, 1],
'Java': [0, 5, 9],
'Spark': [0],
'Storm': [0],
'Cassandra': [0, 1],
'NoSQL': [1],
'MongoDB': [1],
'Postgres': [1],
'Python': [2, 3, 5],
'scikit-learn': [2, 7],
'scipy': [2],
'numpy': [2],
'statsmodels': [2],
'pandas': [2],
'R': [3, 5],
'statistics': [3, 6],
'regression': [3, 4],
'probability': [3, 6],
'machine learning': [4, 7],
'decision trees': [4],
'libsvm': [4],
'C++': [5],
... 'Mahout': [7],
'neural networks': [7, 8],
'deep learning': [8],
'artificial intelligence': [8],
'MapReduce': [9]})
위는 관심사에 따라서 어떤 사람이 그 관심사를 가진지를 매칭시켜줬다.
그렇다면 사람에 따라 관심사를 매칭시키는 것도 해보자.
interests_by_user_id = defaultdict(list)
for user_id, interest in interests:
interests_by_user_id[user_id].append(interest)
interests_by_user_id
defaultdict(list, {0: ['Hadoop', 'Big Data', 'HBase', 'Java', 'Spark', 'Storm', 'Cassandra'],
1: ['NoSQL', 'MongoDB', 'Cassandra', 'HBase', 'Postgres'],
2: ['Python', 'scikit-learn', 'scipy', 'numpy', 'statsmodels', 'pandas'],
3: ['R', 'Python', 'statistics', 'regression', 'probability'],
4: ['machine learning', 'regression', 'decision trees', 'libsvm'],
5: ['Python', 'R', 'Java', 'C++', 'Haskell', 'programming languages'],
6: ['statistics', 'probability', 'mathematics', 'theory'], 7: ['machine learning',
...
8: ['neural networks', 'deep learning', 'Big Data', 'artificial intelligence'],
9: ['Hadoop', 'Java', 'MapReduce', 'Big Data']})
이를 함수로 다시 구현해보자.
- 해당 사용자들의 관심사를 본다
- 각 관심사가 가진 다른 사용자들이 누구인지 찾아본다
- 다른 사용자들이 몇 번이나 등장하는지 본다.
def most_common_interests_with(user):
return Counter(
interested_user_id
for interest in interests_by_user_id[user["id"]]
for interested_user_id in user_ids_by_interest[interest]
if interested_user_id != user["id"]
)
most_common_interests_with(users[0])
Counter({9: 3, 8: 1, 1: 2, 5: 1})
0번의 사람은 9번과 3개의 공통점이 있고, 8번과 1개, 1번과 2개, 5번과 1개의 공통점을 갖고 있다.
1.3.3 연봉과 경력
연봉과 경력의 상관관계를 어떻게 알아볼 수 있을까? 이도 데이터과학으로 할 수 있다.
salaries_and_tenures = [(83000, 8.7), (88000, 8.1),
(48000, 0.7), (76000, 6),
(69000, 6.5), (76000, 7.5),
(60000, 2.5), (83000, 10),
(48000, 1.9), (63000, 4.2)]
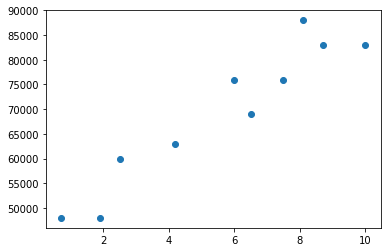
연봉과 직장 경력을 시각화해보았다.
근속연수가 올라갈수록 연봉이 올라가는 거로 보인다.
근속년수와 연봉을 그럼 딕셔너리로 만들어보자.
salary_by_tenure=defaultdict(list)
for salary, tenure in salaries_and_tenures:
salary_by_tenure[tenure].append(salary)
average_salary_by_tenure={
tenure:sum(salaries)/len(salaries)
for tenure, salaries in salary_by_tenure.items()
}
salary_by_tenure
defaultdict(list, {8.7: [83000], 8.1: [88000], 0.7: [48000], 6: [76000], 6.5: [69000], 7.5: [76000], 2.5: [60000], 10: [83000], 1.9: [48000], 4.2: [63000]})
이는 관계를 파악하기가 쉽지가 않다. 경력을 몇 개의 구간으로 나누고 범주를 나눠보자.
def tenure_bucket(tenure):
if tenure<2:
return "less than two"
elif tenure<5:
return "between two and five"
else:
return "more than five"
salary_by_tenure_bucket=defaultdict(list)
for salary, tenure in salaries_and_tenures:
bucket =tenure_bucket(tenure)
salary_by_tenure_bucket[bucket].append(salary)
avaerage_salary_by_bucket={
tenure_bucket: sum(salaries)/len(salaries)
for tenure_bucket, salaries in salary_by_tenure_bucket.items()
}
avaerage_salary_by_bucket
{'more than five': 79166.66666666667, 'less than two': 48000.0, 'between two and five': 61500.0}
범주를 나눠서 이들의 평균 연봉을 계산해봤다.
5년 이상 경력자는 그 이하보다 65%를 더 번다고 한다.
1.3.4 유료 계정
수익관리부에서 어떤 사람이 유료사용자로 전환하는지를 알고 싶다고 한다.
서비스 이용기한과 유료계정을 보면 무슨 상관이 있어보인다.
0.7 paid
1.9 unpaid
2.5 paid
4.2 unpaid
6.0 unpaid
6.5 unpaid
7.5 unpaid
8.1 unpaid
8.7 paid
10.0 paid
서비스 초창기나 후반기는 지불하는 경향이 있고, 중반에는 지불을 안하는 경향이 있는 것 같아 보인다. 이를 바탕으로 새로운 유저가 지불할지 안 지불할지를 예측하는 단순한 함수를 만들어보자.
def predict_paid_or_unpaid(years_exprience):
if years_exprience<3.0:
return "paid"
elif years_exprience <8.5:
return "unpaid"
else:
return "paid"
predict_paid_or_unpaid(5)
'unpaid’
1.3.5 관심주제
사용자들이 보통 어떤 주제에 관심을 갖는지 알아보자.
interests = [
(0, "Hadoop"), (0, "Big Data"), (0, "HBase"), (0, "Java"),
(0, "Spark"), (0, "Storm"), (0, "Cassandra"),
(1, "NoSQL"), (1, "MongoDB"), (1, "Cassandra"), (1, "HBase"),
(1, "Postgres"), (2, "Python"), (2, "scikit-learn"), (2, "scipy"),
(2, "numpy"), (2, "statsmodels"), (2, "pandas"), (3, "R"), (3, "Python"),
(3, "statistics"), (3, "regression"), (3, "probability"),
(4, "machine learning"), (4, "regression"), (4, "decision trees"),
(4, "libsvm"), (5, "Python"), (5, "R"), (5, "Java"), (5, "C++"),
(5, "Haskell"), (5, "programming languages"), (6, "statistics"),
(6, "probability"), (6, "mathematics"), (6, "theory"),
(7, "machine learning"), (7, "scikit-learn"), (7, "Mahout"),
(7, "neural networks"), (8, "neural networks"), (8, "deep learning"),
(8, "Big Data"), (8, "artificial intelligence"), (9, "Hadoop"),
(9, "Java"), (9, "MapReduce"), (9, "Big Data")
]
위의 데이터를 사용해, 단어의 개수를 한 번 세보자.
words_and_counts=Counter(word
for user, interest in interests
for word in interest.lower().split())
for word, count in words_and_counts.most_common():
if(count>1):
print(word,count)
big 3 data 3 java 3 python 3 learning 3 hadoop 2 hbase 2 cassandra 2 scikit-learn 2 r 2 statistics 2 regression 2 probability 2 machine 2 neural 2 networks 2
2번 이상 나온 데이터만 추출했다.
요약
데이터 과학 시스템을 이용해
- 연결관계 파악
- 추천시스템 만들기
- 예측
- 관심사 추측
등을 할 수 있다.
- 연결관계 파악은 각각이 연결된 것을 리스트로 만들어 빈도를 표시할 수 있다
- 추천시스템은 연결관계파악을 기반으로 연결관계 리스트 안의 값을 하나씩 순차탐색하며 그 리스트를 차례로 추가한다.
3)예측은 기준을 정하고 값을 넣는다
- 관심사 추측은 빈도를 센다.
'머신러닝 > 밑바닥부터하는 데이터과학' 카테고리의 다른 글
| 제2장 파이썬 속성강좌 (0) | 2023.05.24 |
|---|---|
| 밑바닥부터 하는 데이터 과학 (0) | 2022.11.24 |
- Total
- Today
- Yesterday
- jlpt
- 일문따
- 일본어
- 파이썬
- 코딩테스트
- 보세사
- 열혈프로그래밍
- 강화학습
- C
- 여인권
- 윤성우
- K-MOOC
- 심리학
- 류근관
- 뇌와행동의기초
- 일본어문법무작정따라하기
- Python
- 회계
- 데이터분석
- 티스토리챌린지
- c++
- 인지부조화
- 백준
- 오블완
- stl
- C/C++
- 통계
- 인프런
- 통계학
- 사회심리학
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |